

 Поделиться
Поделиться
Хозяева сайтов смогут назначать плату компаниям, которые обучают нейросети на их материале. Разработан стандарт
Создатели сайтов смогут требовать плату с компаний, которые используют их контент для обучения нейронных сетей. Новый стандарт лицензирования позволит владельцам ИТ-ресурсов устанавливать условия использования своих материалов и получать выплату за сбор данных языковыми моделями. Инициатором выступила организация RSL Collective, основанная бывшим вице-президентом Yahoo. Многие крупные компании, в том числе Reddit, Yahoo, Medium, Quora, IGN и People Inc., уже объявили о поддержке открытого стандарта.
Новый стандарт лицензирования
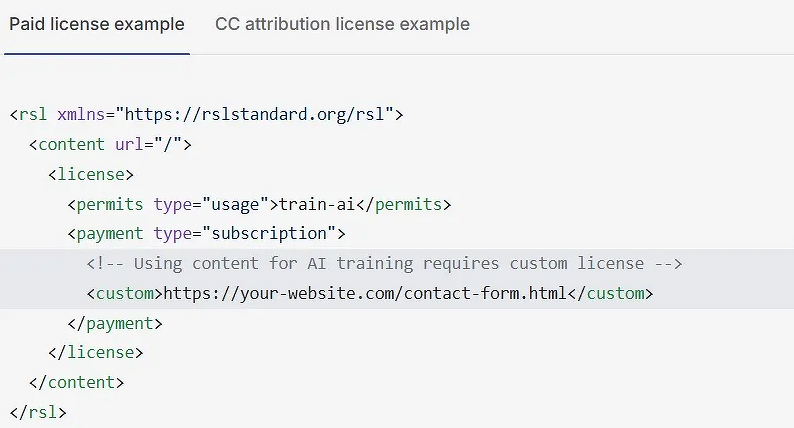
В сентябре 2025 г. представлен открытый стандарт лицензирования контента Really Simple Licensing (RSL), который даст медиакомпаниям возможность определять условия оплаты за сбор ботами данных для обучения искусственного интеллекта (ИИ), пишет The Register. Новый стандарт позволит владельцам ИТ-ресурсов на своих сайтах устанавливать условия использования их произведений. Многие крупные компании, в том числе Reddit, IGN, Yahoo, Medium, Quora и People Inc., уже объявили о поддержке стандарт RSL на своих ресурсах.
Стандарт RSL, основанный на протоколе robots.txt, позволяет издателям указывать поисковым роботам, какие разделы сайта доступны, а какие нет. Однако теперь вместо простого разрешения или запрета сайты могут включать в файл robots.txt условия лицензирования и выплаты вознаграждения. Эти условия также могут быть встроены в онлайн-книги, видео и обучающие наборы данных, требующие компенсации авторам или издателям.
Стандарт RSL поддерживает новая правозащитная организация RSL Collective, которую возглавляют бывший вице-президент Yahoo Экарт Вальтер (Eckart Walter) и соавтор стандарта RSS бывший генеральный директор IAC Publishing и Ask Дуг Лидс (Doug Leeds). «Наша цель — разработать новую масштабируемую бизнес-модель для интернета, — заявил Вальтер. — RSL развивает идеи RSS, создавая новый уровень для всего интернета, где прописаны права на лицензирование и компенсацию».

Стандарт поддерживает различные модели лицензирования, включая бесплатные. Владельцы сайтов могут требовать от компаний, использующих сканеры для обучения нейронных моделей, оплаты подписки или платы за каждое сканирование. Также возможно введение платы за использование контента, когда ИИ-модель ссылается на их материалы при генерации ответа. Боты, сканирующие сайты для других целей, таких как архивирование или индексация в поисковых системах, могут функционировать в стандартном режиме.
Успех стандарта RSL, как и многих других, зависит от поддержки крупных игроков отрасли. Разработчиков ИИ часто обвиняют в игнорировании файлов robots.txt, и без их участия сложно определить размер платы за использование контента. RSL Collective рассчитывает, что объединение крупнейших веб-издателей сделает стандарт более привлекательным. «Наша цель — убедить широкую аудиторию, что это в их интересах. Это эффективно, так как позволяет договориться со всеми сразу, и юридически значимо, ведь нарушение затронет всех одновременно», — отмечает Дуг Лидс.
Заинтересованность на рынке
Ряд медиакомпаний, таких как Vox Media (владелец The Verge), News Corp (владелец The Wall Street Journal) и The New York Times, уже подписали лицензионные соглашения с разработчиками ИИ, включая OpenAI и Amazon. RSL Collective стремится упростить этот процесс, позволяя любому владельцу или создателю сайта получать компенсацию за свой контент без необходимости заключать множество индивидуальных соглашений.
Корпорации осознают, что интеграция ИИ во все их сервисы сопряжена с рисками, поскольку невозможно постоянно использовать ИИ и одновременно вести судебные тяжбы с такими компаниями, как The New York Times, Disney и Universal, которые предъявляют иски. Даже в случае выигрыша в судах процесс может затянуться на годы, а потенциальные штрафы достигают миллиардов долларов. Развитие продукта в условиях риска многомиллиардных штрафов через год-два становится проблематичным. Новый стандарт лицензирования RSL увеличит расходы крупных компаний, внедряющих ИИ, и, вероятно, часть этих затрат будет переложена на пользователей через повышение стоимости подписок.
Поддержку инициативе RSL Collective уже выразили такие компании, как Reddit, Medium и Quora. В то же время другой крупный игрок, Cloudflare, начал предоставлять ИТ-инструменты для блокировки ИИ-ботов еще в 2023 г. Однако, как поясняет советник практики интеллектуальной собственности компании ЭБР Артем Евсеев, несанкционированный сбор данных для обучения нейронных сетей остается в серой зоне правового регулирования: «Нейронные сети используют любой контент, доступный в открытом доступе, независимо от условий его распространения».
Авторское право под угрозой
Успех нового стандарта зависит от того, насколько его поддержат крупные игроки отрасли, говорит партнер компании Digital & Analogue Partners Юрий Брисов: «Отдельные корпорации, в том числе и OpenAI, в сентябре 2025 г. пытаются придумать ИТ-решения, чтобы можно было обучать ИИ-модели на каких-то платных данных, на авторских материалах, и это не было бы нарушением. Плюс необходимо урегулировать механизм, при котором материалы, создаваемые компанией или человеком с использованием ИИ, могут как-то защищаться. Либо копирайт, либо авторское право, либо какой-то новый отдельный механизм защиты права. Потому что ИИ — это технология, за которой в любом случае стоят люди, они используют ИИ при создании контента, но какой-то элемент творчества в этом всегда есть.
По данным Cloudflare, в 2025 г. на одного «живого пользователя» сайтов приходится 14 поисковых роботов Google, 1,7 тыс. запросов от OpenAI и 73 тыс. ботов Anthropic.
По информации «Коммерсант», на данный момент как в России, так и за рубежом использование данных для обучения ИИ остается в серой зоне правового регулирования, особенно в вопросах допустимых исходных данных. Важно учитывать, что контент, находящийся в открытом доступе, распространяется на определенных условиях, которые необходимо соблюдать.
 Короткая ссылка
Короткая ссылка



















