Поделиться
Поделиться
«Яндекс» выложил в открытый доступ альтернативу нейросетям
Выложенная в открытый доступ библиотека машинного обучения CatBoost отличается от традиционных методик алгоритмом градиентного бустинга для гибкого обучения на разнородных данных, в том числе, нечисловых.Гибкое использование числовых и нечисловых данных
«Яндекс» представил новый метод машинного обучения CatBoost и выложил в открытый доступ для всех желающих библиотеку CatBoost на GitHub по лицензии Apache License 2.0. Методика позволяет эффективно обучать модели на разнородных данных — таких как местонахождение пользователя, история операций и тип устройства.
Согласно заявлениям самого «Яндекса», библиотеки CatBoost представляют собой альтернативу нейронным сетям, которые подходят далеко не для всех типов задач реального производства. В таких условиях алгоритм CatBoost обеспечивает более высокую производительность и более устойчивый результат в процессе переобучения и высокую предсказуемость с точки зрения качества конечного результата.
«Яндекс много лет занимается машинным обучением, и CatBoost создавали лучшие специалисты в этой области. Выкладывая библиотеку CatBoost в открытый доступ, мы хотим внести свой вклад в развитие машинного обучения, — сказал Михаил Биленко, руководитель управления машинного интеллекта и исследований «Яндекса». — Надо сказать, что CatBoost — первый российский метод машинного обучения, который стал доступен в Open Source. Надеемся, что сообщество специалистов оценит его по достоинству и поможет сделать ещё лучше».
Как пояснили CNews в «Яндексе», методика CatBoost является наследником метода машинного обучения «Матрикcнет», который применяется почти во всех сервисах «Яндекса». По аналогии с «Матрикснет», CatBoost задействует механизм градиентного бустинга, который хорошо подходит для работы с разнородными данными.
Методика CatBoost интересна сокращенным временем переобучения благодаря применению патентованного алгоритма построения моделей, который, в свою очередь, отличается от стандартной схемы градиентного бустинга.

В отличие от «Матрикснета», обучающего модели на числовых данных, CatBoost учитывает и нечисловые, например, виды облаков или типы зданий. Раньше такие данные приходилось переводить на язык цифр, что могло изменить их суть и повлиять на точность работы модели.
Теперь такие данные можно использовать в первоначальном виде, благодаря чему CatBoost показывает более высокое качество обучения, чем аналогичные методы для работы с разнородными данными. Его можно применять в самых разных областях — от банковской сферы до промышленности.
CatBoost можно запустить прямо из командной строки или воспользоваться удобным для пользователя API для Python или R с инструментами для анализа формул и визуализации обучения.
Как пояснили CNews в пресс-службе «Яндекса», CatBoost - результат долгой работы лучших специалистов компании, который вобрал в себя многолетний опыт компании в разработке ведущих решений в машинном обучении, таких как «Матрикснет». Выкладывая технологию в открытый доступ, «Яндекс» намерен обеспечить серьезный вклад в развитие машинного обучения и рассчитывает, что сообщество специалистов оценит алгоритм по достоинству и поможет сделать его еще лучше.
В «Яндексе» планируют обеспечивать постоянную поддержку проекта. Как пояснили в компании, поддержка будет выражаться в постоянном улучшении алгоритма, а также работе с отзывами пользователей технологии.
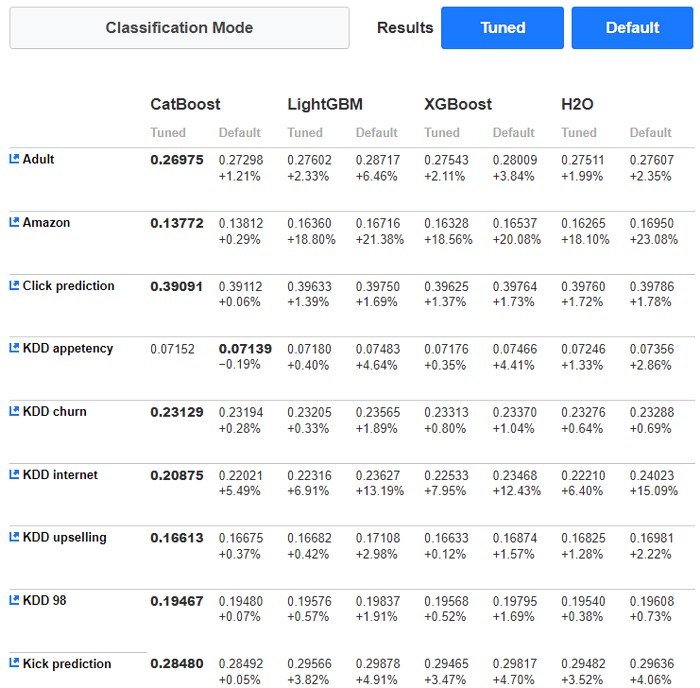
Разработчики также планируют развивать технологию внутри компании: сейчас над ней работает отдельная команда, которые занимается улучшением и внедрением в большее количество сервисов. С течением времени библиотека применений CatBoost будет расти. Поскольку технология выложена в открытый доступ, весь прогресс будет сразу же доступен всем пользователям. Учитывая количество и качество сервисов «Яндекса» и нетривиальные задачи, которые в них решаются, в компании уверены, что технология останется лидирующей в своем классе еще долгое время.
Сегодня в мире существуют разные способы работы с категориальными факторами. Они заключаются в изначальной предобработке и превращении их в числа, пояснили в «Яндексе».
Наиболее эффективный с практической точки зрения способ - это подсчет «счетчиков», его активно используют соревнующиеся на Kaggle, и этот способ используется в победных решениях. В существующих открытых решениях такой способ не используется, а используются более простые методы, такие как one-hot-encoding, они работают обычно хуже. Например, такую предобработку можно использовать в алгоритме lightgbm.
В CatBoost используется более интеллектуальная работа с категориальными факторами, где статистики по ним подсчитываются не заранее, а во время обучения, причем выбираются самые полезные статистики по данным и их комбинациям. One-hot encoding в CatBoost, конечно, тоже поддержан; для характеристик, у которых мало значений иногда такой способ дает плюс в качестве, пояснили в «Яндексе».
Особенность библиотек CatBoost заключается в том, что даже сейчас, в эпоху повсеместного внедрения технологий Deep Learning, для реального производства нейронные сети подходят далеко не для всех типов задач, и в таких условиях градиент бустинг CatBoost обеспечивает более высокую производительность, устойчивость и предсказуемость с точки зрения качества конечного результата.
Практические приложения
CatBoost уже протестировали на сервисах «Яндекса». В рамках эксперимента он применялся для улучшения результатов поиска, ранжирования ленты рекомендаций «Яндекс.Дзен» и для расчета прогноза погоды в технологии «Метеум». Во всех случаях технология показала себя лучше «Матрикснета».
В дальнейшем CatBoost будет работать и на других сервисах, отмечают в «Яндексе». Его использует также команда Yandex Data Factory — в своих решениях для промышленности, в частности для оптимизации расхода сырья и предсказания дефектов.
CatBoost уже имеет опыт международного использования: этот метод машинного обучения был внедрен Европейским центром ядерных исследований (ЦЕРН) для объединения данных, полученных с разных частей детектора LHCb.
Данные, собранные в ходе эксперимента, обрабатываются для индивидуальных столкновений с помощью CatBoost со скоростью 40 миллионов в секунду.
Доступность CatBoost
Для работы с CatBoost достаточно установить его на свой компьютер. Библиотека поддерживает операционные системы Linux, Windows и macOS и доступна на языках программирования Python и R.
«Яндекс» разработал также программу визуализации CatBoost Viewer, которая позволяет следить за процессом обучения на графиках. Скачать CatBoost и CatBoost Viewer можно на GitHub.
 Короткая ссылка
Короткая ссылка