Поделиться
Поделиться
EMC радикально обновляет решения для резервирования и хранения данных
Как шутят специалисты, на эффективность систем хранения данных влияют два фактора: вдохновение и отчаяние администраторов, и умный человек сможет использовать оба. Но в период массовых отпусков у многих ИТ-директоров есть время подготовиться к очередному всплеску деловой активности: изучить новые решения и поразмыслить над улучшением ИТ-инфраструктуры. Сегодня мы рассмотрим обновления среди решений EMC для резервного копирования и восстановления данных.Хотя Уильям Дженкинс, президент подразделения EMC Backup Recovery Systems, и говорит о связке Data Domain – Avamar как о комплексном решении, данные продукты разрабатывались порознь и для различных целей. "Avamar и Data Domain создавались для решения разных клиентских задач, – уточнил Дженкинс. – Решения Data Domain разрабатывались как репозитории для бэкапов и для того, чтобы повысить эффективность резервного копирования в зонах хранения данных. Avamar же было создано как более традиционное приложение для резервного копирования. Оно хорошо работает на десктопах, ноутбуках и в удаленных офисах. Таким образом, у нас получилось два продукта".
Тем не менее, ЕМС работает над полной интеграцией Data Domain, Avamar и третьего решения компании – NetWorker – и возможно, это займет определенное время.
Почему так, а не иначе?
Напомним, что решения EMC Avamar и EMC DataDomain используют алгоритмы дедупликации с переменной длиной блоков – они в целом сложнее алгоритмов с блоками фиксированной длины (границу блоков определить непросто), но обычно дают больший эффект. При этом процесс дедупликации происходит в режиме inline (поточная дедупликация), когда сначала обрабатываются данные, а потом уникальные блоки и "схемы сборки" данных пишутся на диск. Такой подход позволяет более эффективно использовать дисковое пространство и увеличить скорость восстановления информации, в отличие от метода post-processing, где данные сначала пишутся на диск, а потом в фоновом режиме идет их дедупликация.
Для неспециалистов стоит пояснить особенности дедупликации на уровне блоков. Современные технологии дедупликации делятся на следующие виды:
Файловая дедупликация – самый старый способ уменьшить количество хранимых данных. Если система находит два или более одинаковых файла – она заменяет все, кроме первого, на ссылки на первый файл. За счет этого количество хранимых файлов уменьшается. Однако если файлы различаются хотя бы на один бит, система будет считать их разными и дедупликации не произойдет.
Блочная дедупликация. В данном случае каждый файл на диске будет разбит на несколько блоков заранее заданной или переменной, в зависимости от алгоритма, длины. В хранилище отправятся только уникальные блоки и "схема сборки" блоков в файл. Таким образом, коэффициент дедупликации будет существенно выше, чем у файловой дедупликации.
"При таком подходе к хранению данных, в хранилище, как в детском конструкторе, лежат только простые "кирпичики" и "чертежи" будущих строений. Так же как и в случае с конструктором, собрать из одного набора "кирпичиков" можно огромное количество разных конструкций", – рассказывает Михаил Зарубин. – Дедупликация с переменной длиной блока более эффективна. Для примера возьмем какое-нибудь предложение, например: Василиск Василий очень любил чеснок. Оно занимает 35 символов (включая пробелы). При использовании дедупликации с фиксированным блоком мы получим следующие блоки: "Вас", "или", "ск", "й о", "чен", "ь л", "юби", "л ч", "есн", "ок.". Количество хранимых символов уменьшилось до 30, но добавилась "схема сборки". При использовании дедупликации с переменным блоком получим: "Вас", "ил", "иск", " " , "ий", "о", "че", "нь", "люб", "сн", "к.". Количество хранимых символов уменьшилось до 23, и снова добавилась "схема сборки"".
Таким образом можно достичь высокой эффективности хранения резервных копий.
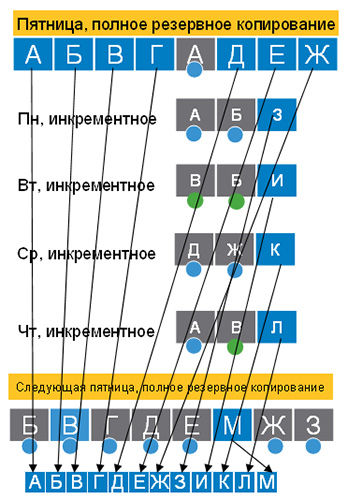
Алгоритм работы хранилища
Системы Data Domain хранят данные на жестких дисках (а иначе нельзя эффективно использовать дедупликацию), поэтому позволяют восстанавливать информацию одновременно нескольких клиентов в отличие от ленточных хранилищ, где один привод может восстанавливать данные только одного клиента в каждый момент времени.
Сравнение ленточных и дисковых накопителей – тема для отдельного разговора. Решение об их применении принимается исходя из требований бизнеса клиента и особенностей его ИТ-инфраструктуры. К тому же, как мы видим, ЕМС теперь идет на компромисс и не ограничивает пользователей в выборе. А направление на более тесную интеграцию своих продуктов не только между собой, но и с системами сторонних вендоров может избавить от многих проблем, как на этапе внедрения, так и в процессе эксплуатации.
Ирина Матюшонок / CNews
 Короткая ссылка
Короткая ссылка